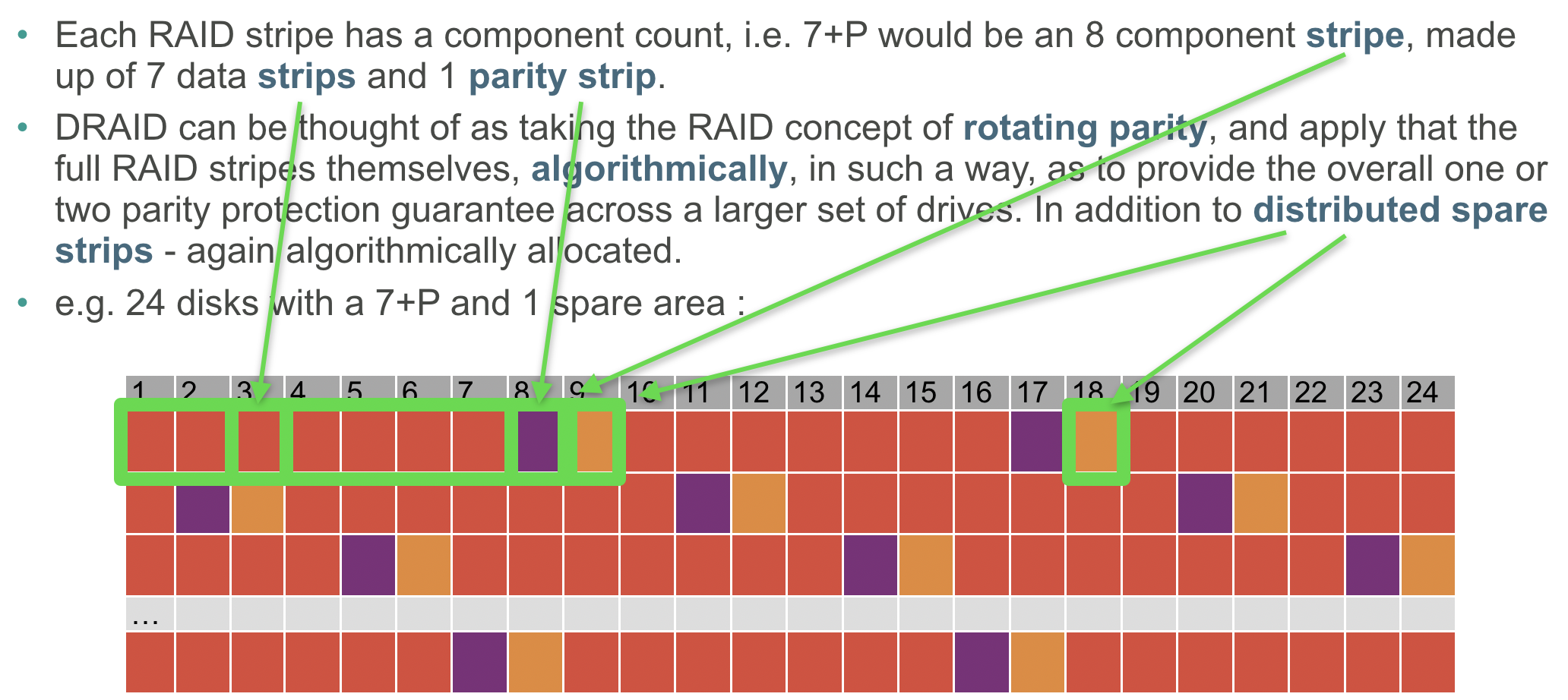
Hey, Chris with iX here. dRAID can be confusing, perhaps more so for users who are familiar with RAIDz than those who are new to ZFS in general as some of the terminology is similar and some is dissimilar.
In general a single zdev is ideal for dRAID as the distributed spares are shared across the entire vdev, multiple vdevs would require proportionally more spares to provide the same level of spare availability. In dRAID configurations
redundancy groups are similar in function to vdevs in a RAIDz pool. A redundancy group is composed of a number of data devices and a number of parity devices, and a number of redundancy groups will make up a single dRAID vdev. Data is striped across redundancy groups, providing a similar performance benefit to multiple vdevs in a RAIDz pool.
For me personally, it helped to look at the ZFS CLI commands to better understand how a dRAID vdev is constructed.
Code:
zpool create tank draid2:8d:2s:22c /dev/sd[...]
This statement creates a single dRAID vdev.
draid2 indicates a parity level, P, of 2 per redundancy group.
8d indicates 8 data devices, D, per redundancy group.
2s indicates 2 distributed spares, S, which are distributed across the entire vdev.
22c indicates the number of children, C, or total number of drives in the dRAID vdev.
The number of redundancy groups can be calculated as follows:
Code:
number of redundancy groups = (C - S)/(D + P)
So in this case we would have (22 - 2)/(2 + 8), which results in 2 redundancy groups. Data will be striped across these 2 redundancy groups which each have 10 total disks. Creation of this same pool using the TrueNAS WebUI is as follows:
dRAID pools may not be a "one size fits all" solution, but is most valuable with large pools composed of large disks as resilver time is greatly improved of RAIDz and the pool can get back to a healthy state far faster. Part of this increase in speed is because dRAID uses a sequential resilver, in which blocks are read and restored sequentially and a scrub is performed after the resilver to verify checksums, unlike in a RAIDz resilver where the entire block tree is traversed and checksums are verified during the resilver.
The cost of using sequential resilver is the requirement to use fixed stripe width. In the above example, using 4k sector disks, the minimum allocation size is 32k (8 data devices, D, multiplied by 4K sectors). Any files smaller than 32k will be padded with 0's to take up an entire stripe. This could have a largely negative impact for certain use cases, such as databases. In addition best storage utilization will occur when the data devices are a power of 2, which will align with ZFS record sizes.
One other caveat is that dRAID pools depend on precomputed permutation maps to determine where data, parity, and spare capacity reside across the pool, this ensures that during resilvers IO is distributed equally across all members of the vdev. Because of this, distributed spares cannot be added or removed after creation, unlike spares in a RAIDz pool.
Please let me know if that helps, happy to clear up any questions.